MongoDB 工作常用操作命令
Help 指令帮助
help #命令提示符
db.help() #数据库方法帮助信息
db.mycoll.help() #集合方法帮助信息
切换/创建数据库
#假如已经存在的数据库会直接切换到指定的数据库
use testDb
#当创建一个新的数据库需要创建一个集合(table)的时候才会把数据库持久化到磁盘中
【可能一开始创建数据库时,是在内存中的,还没有持久化到磁盘。新建集合时,就持久化了】
use testDb
db.createCollection(“mybooks”)
数据库查看
show dbs #查看所有数据库
db 或 db.getName() #查看当前使用的数据库
显示当前 db 状态
db.stats()
查看当前 db 版本
db.version()
查看当前 db 的连接服务器机器地址
db.getMongo()
删除当前使用数据库
db.dropDatabase()
查询之前的错误信息和清除
db.getPrevError()
db.resetError()
Collection 集合创建、查看、删除
集合创建
db.createCollection(“MyBooks”) #MyBooks 集合名称
查看当前数据库中的所有集合
show collections
集合删除
db.MyBooks.drop() #MyBooks 要删除的集合名称
Document 文档增删改查
文档插入
insert 多个文档插入
MongoDB使用 insert() 方法向集合中插入一个或多个文档,语法如下:
db.COLLECTION_NAME.insert(document)
注意:insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。
示例:
添加数据源:
[{
name: "追逐时光者",
phone: "15012454678"
}, {
name: "王亚",
phone: "18687654321"
}, {
name: "大姚",
phone: "13100001111"
}, {
name: "小袁",
phone: "131054545541"
}]
多条文档数据插入:
db.Contacts.insert([{
name: "追逐时光者",
phone: "15012454678"
}, {
name: "王亚",
phone: "18687654321"
}, {
name: "大姚",
phone: "13100001111"
}, {
name: "小袁",
phone: "131054545541"
}])
查看插入文档数据:
db.Contacts.find()
insertOne 一个文档插入
insert() 方法可以同时插入多个文档,但如果您只需要将一个文档插入到集合中的话,可以使用 insertOne() 方法,该方法的语法格式如下:
db.COLLECTION_NAME.insertOne(document)
示例:
添加数据源:
{
bookName: "平凡的世界",
author: "路遥"
}添加示例:
db.MyBooks.insertOne({
bookName: "平凡的世界",
author: "路遥"
})
文档更新
update() 方法用于更新已存在的文档。语法格式如下:
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
参数说明:
query : update 的查询条件,类似 sql update 查询内 where 后面的。
update : update 的对象和一些更新的操作符(如$,$inc…)等,也可以理解为 sql update 查询内 set 后面的
upsert : 可选,这个参数的意思是,如果不存在 update 的记录,是否插入 objNew,true 为插入,默认是 false,不插入。
multi : 可选,mongodb 默认是 false,只更新找到的第一条记录,如果这个参数为 true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。
示例:
更改 bookName:”平方的世界”书籍名称改成“平方的世界”
db.MyBooks.update({'bookName':'平方的世界'},{$set:{'bookName':'平凡的世界'}})
文档查询
MongoDB 查询数据的语法格式如下:
db.collection.find(query, projection)
query :可选,使用查询操作符指定查询条件
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下:
db.col.find().pretty()
pretty() 方法以格式化的方式来显示所有文档。
查询 Contacts 集合中的所有数据:
db.Contacts.find().pretty()
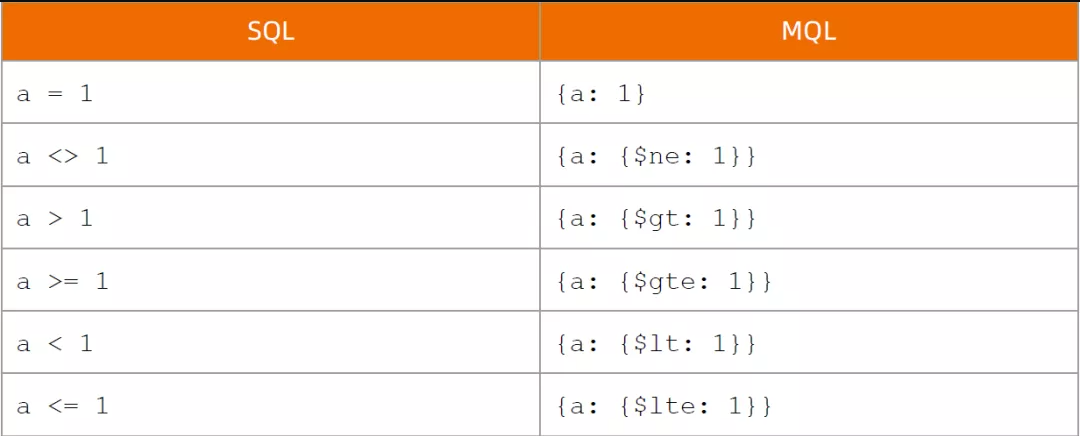
MongoDB 与 RDBMS Where 语句比较:
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
操作 格式 范例 RDBMS 中的类似语句
等于 {<key>:<value>} db.col.find({“by”:”菜鸟教程”}).pretty() where by = ‘菜鸟教程’
小于 {<key>:{$lt:<value>}} db.col.find({“likes”:{$lt:50}}).pretty() where likes < 50
小于或等于 {<key>:{$lte:<value>}} db.col.find({“likes”:{$lte:50}}).pretty() where likes <= 50
大于 {<key>:{$gt:<value>}} db.col.find({“likes”:{$gt:50}}).pretty() where likes > 50
大于或等于 {<key>:{$gte:<value>}} db.col.find({“likes”:{$gte:50}}).pretty() where likes >= 50
不等于 {<key>:{$ne:<value>}} db.col.find({“likes”:{$ne:50}}).pretty() where likes != 50
MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
语法格式如下:
db.col.find({key1:value1, key2:value2}).pretty()
查询集合(Contacts)中 name=“小袁” 和 phone=”131054545541″记录:
db.Contacts.find({“name”:”小袁”, “phone”:”131054545541″}).pretty()
MongoDB OR 条件
MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
db.col.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()查询集合(Contacts)中 name=“小袁” 和 name=”大姚”记录:
db.Contacts.find({$or:[{"name":"小袁"},{"name": "大姚"}]}).pretty()
AND 和 OR 联合使用
以下实例演示了 AND 和 OR 联合使用,类似常规 SQL 语句为: ‘where age>18 AND (“name”=”小袁” OR “name”=”大姚”)’:
db.Contacts.find({"age": {$gt:18}, $or: [{"name":"小袁"},{"name": "大姚"}]}).pretty()
文档删除
remove() 方法的基本语法格式如下所示:
db.collection.remove(
<query>,
{
justOne: <boolean>, writeConcern: <document>
}
)参数说明:
query:必选项,是设置删除的文档的条件。
justOne:布尔型的可选项,默认为 false,删除符合条件的所有文档,如果设为 true,则只删除一个文档。
writeConcem:可选项,设置抛出异常的级别。
1、根据某个 _id 值删除数据:
#_id 为字符串的话,可以直接这样
db.collection.remove({"_id":"你的 id"});
#_id 由 MongoDB 自己生成时
db.collection.remove({'_id':ObjectId("636680729003374f6a6c7add")})
2、移除 title 为“MongoDB”的文档:
db.colection.remove({'title': 'MongoDB'})
MongoDB Limit 与 Skip 方法
Contacts 集合数据展示
MongoDB Limit 方法
如果你需要在 MongoDB 中读取指定数量的数据记录,可以使用 MongoDB 的 Limit 方法,limit()方法接受一个数字参数,该参数指定从 MongoDB 中读取的记录条数。
语法:
limit()方法基本语法如下所示:
db.COLLECTION_NAME.find().limit(NUMBER)
示例:
查询 Contacts 集合中的前两条数据:
注意:如果没有指定 limit()方法中的参数则显示集合中的所有数据。
db.Contacts.find().limit(2)
MongoDB Skip 方法
我们除了可以使用 limit()方法来读取指定数量的数据外,还可以使用 skip()方法来跳过指定数量的数据,skip 方法同样接受一个数字参数作为跳过的记录条数。
语法
skip() 方法脚本语法格式如下:
db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)
实例
查询 Contacts 集合中的第 2 条数据:
# 显示一条如何在跳过一条
db.Contacts.find().limit(1).skip(1)MongoDB 排序
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法
sort()方法基本语法如下所示:
db.COLLECTION_NAME.find().sort({KEY:1})
示例
在 Contacts 集合中让 name 按照降序来排列:
db.Contacts.find().sort({"name":-1})
MongoDB 索引
说明
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB 在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
语法
createIndex()方法基本语法格式如下所示:
注意:语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
db.collection.createIndex(keys, options)
createIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background 可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为 false。 |
| unique | Boolean | 建立的索引是否唯一。指定为 true 创建唯一索引。默认值为 false. |
| name | string | 索引的名称。如果未指定,MongoDB 的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为 true 的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL 设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于 mongod 创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的 language,默认值为 language. |
实例
1、为 Contacts 集合中的 name 字段按降序设置索引
db.Contacts.createIndex({“name”:-1})
2、为 Contacts 集合中的 name 字段和 phone 字段同时按降序设置索引(关系型数据库中称作复合索引)
db.Contacts.createIndex({“name”:-1,”phone”:-1})
3、以后台方式给 Contacts 集合中的 phone 字段按降序设置索引
db.Contacts.createIndex({“phone”: 1}, {background: true})
MongoDB 聚合
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
类似 SQL 语句中的 count(*)。
语法
aggregate() 方法的基本语法格式如下所示:
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
首先创建一个 BlogCollection 集合,并批量插入多个文档数据:
#创建集合 use BolgCollection
#批量插入集合文档数据
db.BlogCollection.insert([{
title: '学习 MongoDB',
description: 'MongoDB is no sql database',
by_user: '时光者',
likes: 100
},
{
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: '时光者',
likes: 10
},
{
title: '.Net Core 入门学习',
description: '.Net Core 入门学习',
by_user: '大姚',
likes: 750
},
{
title: 'Golang 入门学习',
description: 'Golang 入门学习',
by_user: '小艺',
likes: 750
}])
#查询集合所有文档数据
db.BlogCollection.find()
$sum 分组统计以上 BlogCollection 集合每个作者所写的文章数:
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
类似于 SQL 语句:
select by_user, count(*) from BlogCollection group by by_user
$sum 计算 likes 的总和
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])
$avg 计算 Likes 的平均值
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])
$min 获取集合中所有文档对应值得最小值:
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])
$max 获取集合中所有文档对应值得最大值:
db.BlogCollection.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])

![【学习强国】[挑战答题]带选项完整题库(2020年4月20日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/timg-300x200.jpg)


![【学习强国】[新闻采编学习(记者证)]带选项完整题库(2019年11月1日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/77ed36f4b18679ce54d4cebda306117e-300x200.jpg)


{kind=link}
{kind=link}