
Elasticsearch是一个分布式系统,具有高可用性及可扩展性,当集群中有节点停止或丢失时不会影响集群服务或造成数据丢失;同时当访问量或数据量增加时可用采用横向扩展的方式增加节点,将请求或数据分散到集群的各个节点上。不同的集群可以通过不同的名字来区分,集群默认名为“elasticsearch“,如果节点配置的集群名称一样,则这些节点组成为一个ES集群。一个节点是一个 ElasticSearch 的实例,本质上是一个 Java 进程。ES 根据功能不同分为不同的节点类型,在生产环境中,建议根据数据量,写入及查询吞吐量,选择合适的部署方式,最好将节点设置为单一角色。 | | | |
| 管理节点,进行创建、删除索引等操作,决定分片被分配到哪个节点,负责索引创建删除,维护并更新集群状态。 | | |
| 数据节点,处理与数据相关的操作,如索引的 CRUD、搜索和聚合,数据节点的操作属于 I/O、内存和 CPU 密集型操作。 | | |
| 提取节点,具有数据预处理的能力,可拦截 Index 或 Bulk Api 的请求,可对数据进行转换,并重新返回 Index 或 Bulk Api,默认配置下,所有节点都是 Ingest Node。 | | |
| 协调节点,负责接受客户端的请求,并将请求分发到合适的节点,并将各节点返回的数据汇聚到一起。每个节点都默认是 Coordinating Node。 | | 设置 master、data、ingest 全为 false |
| 机器学习节点,用于运行作业和处理机器学习 API 请求。 | | |
文档是 ES 的最小单位,通常用 JSON 方式的数据结构表示,类似于数据库中的一条记录。文档具有以下特征:3.灵活的结构,不依赖于预先定义的模式,文档是无模式的,并非所有的文档都需要拥有相同的字段。类型是文档的逻辑容器,类似于数据库中的表,类型在 Elasticsearch中表示一类相似的文档,每个类型中字段的定义称为映射。ES7.x 已经将类型移除,7.x 中一个索引只能有一个类型,默认为 _doc。mapping 映射, 就像数据库中的 schema ,定义索引中字段的名称、字段的数据类型(如 string, integer 或 date),设置字段倒排索引的相关配置。当索引文档遇到未定义的字段,会使用 dynamic mapping 来确定字段的数据类型,并自动把新增加的字段添加到类型映射。在实际生产中一般或禁用 dynamic mapping,避免过多的字段导致 cluster state 占用过多,同时禁止自动创建索引的功能,创建索引时必须提供 Mapping 信息或者通过 Index Template 创建。一个分片是一个运行的 Lucene 的实例,是一个包含倒排索引的文件目录。一个ES 索引由一个或多个主分片以及零个或多个副本分片组成,主分片数在索引创建时指定,后续不允许修改;副本分片主要用于解决数据高可用的问题,是主分片的拷贝,一定程度上提高服务的可读性。分片的设定:生产环境中主分片数的设定,需要提前做好容量规划,因为主分片的数量是不可修改的。如果分片数设置过小,则无法通过增加节点实现水平扩展,单个分片的数据量太大,导致数据重新分片耗时;如果分片数设置过大,则会影响搜索结果的相关性打分,浪费资源,同时影响性能。在了解了 ES 的基本概念之后,我们通过一张图来探索一下ES 索引的全流程:客户端向ES 节点发送索引请求,以 RestClient 客户端发起请求为例,ES 提供了 Java High Level REST Client,可以通过 RestClient 发送请求:其中 127.0.0.1,127.0.0.2是 ES 节点地址,充当 coordinate node 节点的角色,接收客户端请求,如果设置有专用 coorinate node 则应该将接受客户端请求的节点设置为该专用节点,负责请求的接受和转发。在 RestClient 中使用 round-robin 轮询算法,进行发送节点的选取。对请求中的参数进行检查,检查参数是否合法,不合法的参数直接返回失败给客户端。如果请求指定了 pipeline 参数,则对数据进行预处理,数据预处理的节点为 Ingest Node,如果接受请求的节点不具备数据处理能力,则转发给其他能处理的节点。在 Ingest Node 上有定义好的处理数据的 Pipeline,Pipeline 中有一组定义好的 Processor,每个 Processor 分别具有不同的处理功能,ES 提供了一些内置的 Processor,如:split、join、set 、script 等,同时也支持通过插件的方式,实现自定义的 Processor。数据经过 Pipeline 处理完毕后继续进行下一步操作。判断索引是否存在。如果索引不存在,则判断是否能够自动创建,可以通过 action.auto_create_index 设置能否自动创建索引;如果节点支持 Dynamic Mapping,写入文档时,如果字段尚未在 mapping 中定义,则会根据索引文档信息推算字段的类型,但并不能完全推算正确。配置 Dynamic:true 时,文档有新增字段的时候,索引的 mapping 也会同步更新。Dynamic:false 时,索引的 mapping 不会被更新,新增字段无法被索引到。Dynamic:strict 时,索引有新增字段时,将会报错。创建索引请求被发送到 Master 节点,由 Master 节点负责进行索引的创建,索引创建成功后,Master 节点会更新集群状态 clusterstate,更新完毕后将索引创建的情况返回给 Coordinate 节点,收到 Master 节点返回后,进入下一流程。2)从集群状态中获取对应索引的元信息,从元信息中获取索引的 mapping、version 等信息,从请求中解析 routing、id 信息,如果请求没有指定文档的 id,则会生成一个 UUID 作为文档的 id。根据请求的 routing、id 信息计算文档应该被索引到哪个分片,计算公式为:shard_num = hash(_routing) % num_primary_shards其中_routing 默认值为文档 id,num_primary_shards 是主分片个数,所以从算法中即可以看出索引的主分片个数一旦指定便无法修改,因为文档利用主分片的个数来进行定位。当使用自定义 _routing 或者 id 时,按照上面的公式计算,数据可能会大量聚集于某些分片,造成数据分布不均衡,所以 ES 提供了 routing_partition_size 参数,routing_partition_size 越大,数据的分布越均匀。此时分片的计算公式变为:shard_num = (hash(_routing) + hash(_id) % routing_partition_size) % num_primary_shards定位到分片序号后,还需要定位分片所属的数据节点;从集群状态的内容路由表获取主分片所在的节点,并将请求转发至节点。需要注意的是分片到数据节点的映射关系不是固定的,当检测到数据分布不均匀、新节点加入或者节点宕掉等会进行分片的重新分配。当主分片所在节点接受到请求后,节点开始进行本节点的文档写入,文档写入过程:1)文档写入时,不会直接写入到磁盘中,而是先将文档写入到 Index Buffer 内存空间中,到一定的时间,Index Buffer 会 Refresh 把内存中的文档写入 Segment 中。当文档在 Index Buffer 中时,是无法被查询到的,这就是 ES 不是实时搜索,而是近实时搜索的原因。2)因为文档写入时,先写入到内存中,当文档落盘之前,节点出现故障重启、宕机等,会造成内存中的数据丢失,所以索引写入的同时会同步向 Transaction Log 写入操作内容。3)每隔固定的时间间隔 ES 会将 Index Buffer 中的文档写入到 Segment 中,这个写入的过程叫做 Refresh,Refresh 的时间可以通过 index.refresh_interval设置,默认情况下为 1 秒。4)写入到 Segment 中并不代表文档已经落盘,因为 Segment 写入磁盘的过程相对耗时,Refresh 时会先将 Segment 写入缓存,开放查询,也就是说当文档写入 Segment 后就可以被查询到。每次 refresh 的时候都会生成一个新的 segment,太多的 Segment 会占用过多的资源,而且每个搜索请求都会遍历所有的 Segment,Segment 过多会导致搜索变慢,所以 ES 会定期合并 Segment,减少 Segment 的个数,并将 Segment 和并为一个大的 Segment;在操作 Segment 时,会维护一个 Commit Point 文件,其中记录了所有 Segment 的信息;同时维护.del 文件用于记录所有删除的 Segment 信息。单个倒排索引文件被称为 Segment。多个 Segment 汇总在一起,就是 Lucene 的索引,对应的就是 ES 中的 shard。单词词典:记录所有文档的单词,记录单词到倒排列表的关系,数据量比较大,一般采用 B+树,哈希拉链法实现。倒排列表:记录单词对应的文档集合,由倒排索引项组成。倒排索引项结构如表所示:文档 ID:记录单词所在文档的 ID;词频:记录单词在文档中出现的次数;位置:记录单词在文档中的位置;偏移:记录单词的开始位置,结束位置。 5)每隔一定的时间(默认 30 分钟),ES 会调用 Flush 操作,Flush 操作会调用 Refresh 将 Index Buffer 清空;然后调用 fsync 将缓存中的 Segments 写入磁盘;随后清空 Transaction Log。当 Transaction Log 空间(默认 512M)后也会触发 Flush 操作。当主分片完成索引操作后,会循环处理要写的所有副本分片,向副本分片所在的节点发送请求。副本分片执行和主分片一样的文档写入流程,然后返回写入结果给主分片节点。主分片收到副本分片的响应后,执行 finish()操作,将收到响应信息返回给 Coordinate 节点,告知 Coordinate 节点文档写入的情况;coordinate 节点收到响应后,将索引执行情况返回给客户端。至此一个文档索引的全过程结束,用户可通过 ElasticSearch 提供的接口进行数据的查询。ElasticSearch 自诞生以来,使用热度越来越高,功能越来越强大。ES 不仅支持分布式、可扩展,还提供了 RestFul 风格接口,方便应用接入使用;适用于所有的数据类型,具备存储海量数据能力,拥有高性能的近实时检索功能,同时还提供了数据的近实时分析功能;适用于海量数据的近实时检索、分析,在日志、监控数据存储分析,集中式全文搜索方面应用较为广泛。 © 版权声明
博主的文章没有高度、深度和广度,只是凑字数。利用读书、参考、引用、抄袭、复制和粘贴等多种方式打造成自己的纯镀 24k 文章!如若有侵权,请联系博主删除。
喜欢就点个赞吧


![【学习强国】[挑战答题]带选项完整题库(2020年4月20日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/timg-300x200.jpg)


![【学习强国】[新闻采编学习(记者证)]带选项完整题库(2019年11月1日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/77ed36f4b18679ce54d4cebda306117e-300x200.jpg)





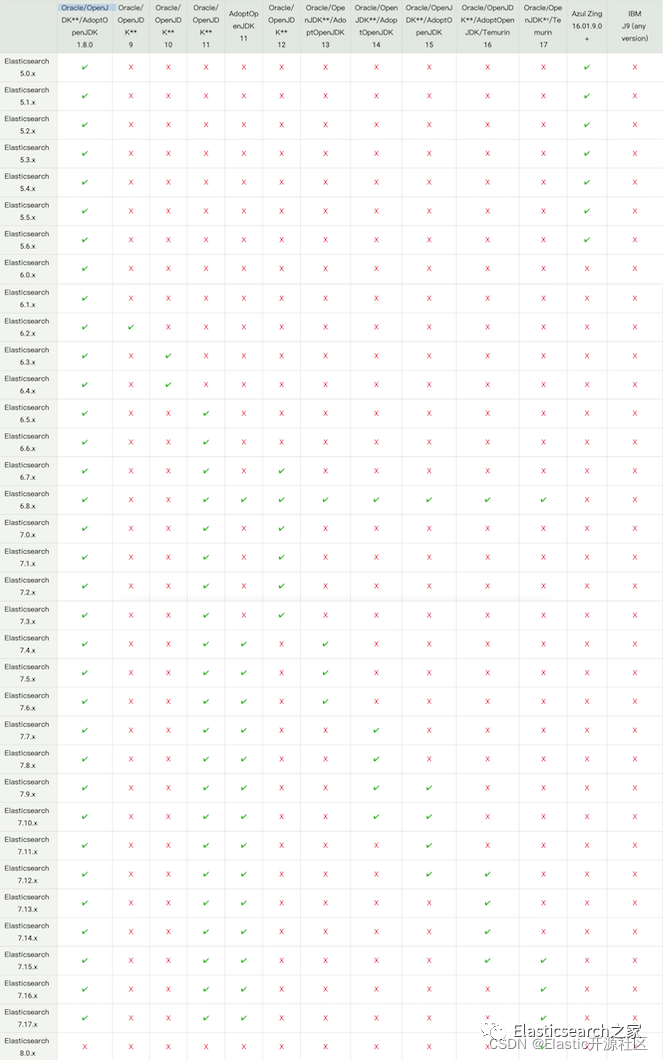
{kind=link}
{kind=link}