前言
现在遇到高并发场景时,缓存技术应该算是性能优化的第一步,缓解数据库压力的同时还能提高访问效率,而Redis应该是绝大多数应用场景的首选。但是尽快Redis性能再优秀,在当今高并发场景下,一台服务器负责读写,机器的性能和内存的瓶颈肯定避免不了,到这肯定有小伙伴会想到集群, 对的,思路没错,只是在集群之前,主从复制模式的优化策略能解决很多问题,如果主从模式还抗不住高并发,那再来集群也不晚;这里先来说说 Redis 的主从复制。
为了更好的演示,搞了一台云服务器,Linux 环境;方便的同时,也能更符合实际应用场景;
正文
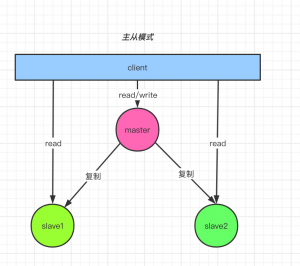
主从复制:主从指有多台Redis服务器,其中一台为主服务器,其他为从服务器,可以通过命令或配置实现主从关系;复制指将主服务器的数据同步到从服务器,数据只能从主服务器向从服务器单向同步;其作用如下:
•读写分离:主服务器复制写,各从服务器负责读;根据二八原则,80%的操作都是读,只有 20%进行写,所以在一定程度上也解决了单机瓶颈问题;•数据持久化更加安全:主从多台服务器进行持久化操作,任意一台服务宕机也不会影响数据恢复,避免了单点故障问题;•其他:主从复制是实现哨兵模式和Redis集群的前提,这个后续会说到。
好啦,老规矩,了解其作用之后,接下来就先实操再总结。
实现主从复制
每一台Redis服务器启动时,默认都是主服务器(Master),可以通过命令info replication查看,如下图所示:

开始实操搭建一主二从的环境,如下:

1. 配置文件修改
由于是在同一台机器上模拟,所以将 redis 配置文件拷贝三份出来,主要修改项如下:
•配置文件名称:分别为 redis.conf、redis6388.conf、redis6399.conf;•port:端口,三个配置文件分别修改为 6379、6388、6399,这是为了避免同一台机器演示端口冲突;•pidfile:修改此文件名,避免文件冲突,改文件名即可,分别修改为 redis.pid、redis6388.pid、redis6399.pid;•dbfilename:持久化文件名,避免持久化文件冲突,分别修改为 dump.rdb、dump6388.rdb、dump6399.rdb;
2. 启动 redis 服务器
然后分别指定配置文件启动 redis-server,在 redis 中 bin 目录下执行./redis-server redis.conf、./redis-server redis6388.conf、./redis-server redis6399.conf命令即可,可以通过命令ps -ef | grep redis查看启动 redis 效果,如下:

3.1 使用命令实现主从关系
默认情况下,启动的三台服务器默认都是主服务器,现在可以通过简单的命令实现一主二从的关系,这里以 6379 这台服务器为主,6388 和 6399 两台服务器为从,配置主从关系只针对从节点服务器配置即可,如下:
1.分别连上 6388 和 6399 两台服务器,执行slaveof masterip masterport即可:

2.从节点显示没问题,看看主节点状态信息,连上 6379 这台看看,如下:

3.主从关系维护好了,接下来看看数据复制,通常主节点负责写,将数据同步到从节点,从节点负责读;现在三台服务器都没数据,接下来往主节点中写入点数据,看看是否能同步到从节点:

注:如果通过命令方式实现主从关系,那当从服务器重启时,主从关系就丢了,还得手动再执行命令,所以推荐配置文件的形式进行配置;
3.2 通过配置文件实现主从配置
还是很简单的,主服务器不用动,仅修改从服务器配置文件,然后重启即可,根据前面章节的学习经验,打开配置文件,直接找到REPLICATION模块进行如下配置修改:
•replicaof <masterip> <masterport> :指定主节点 ip 和端口即可,如:replicaof 127.0.0.1 6379;•masterauth <master-password>:指定主节点密码,如果主节点配置密码,直接通过这配置就行;
修改完这两项,重启服务器即可,和命令行一样简单,只是通过配置文件搭建的主从关系不会因为关闭服务器而丢失;这里配置文件的演示就不截图了,只是实现方式不一样,其他都是和命令行一致;
小总结
•配从不配主,即只针对从服务器配置即可,主服务器无需配置;•一个主节点有多个从节点,从节点只能有一个主节点;从节点也可以作为其他从节点的主节点,如下:

这种方式的演示截图就不提供了,小伙伴实操一把,这里说明一下,虽然 6388 是 6399 的主 节 点,但扮演的角色还是 6379 的从节点,只是它下面连接了其他从节点而已; •如果用命令方式实现主从,主服务器断开后,重新连接,主从关系还在;从服务器断开之后重连关系消失,需要手动执行命令重新指定主节点; •如果希望断开重连主从关系还在,推荐配置文件方式实现;
实现主从复制的搭建是不是很简单,不管是命令还是配置文件的方式,都很轻松实现;但小伙伴是不是也有疑问:主从节点之间的数据是如何同步的?关于主从复制的其他参数有什么用?
主从复制原理
通过上面实操,在主服务器中写入的数据,在无感知的情况下就同步到各个从服务器,中间到底经历了什么呢?接下来简单的了解一下;
在Redis2.8 之前同步方式都以全量方式同步,之后为了提高效率,数据复制方式分为两种,一种为全量复制,一种为部分复制:
•全量复制:即将主服务器中的数据,全部同步到从服务器;一般是在从服务器启动初始化数据的时候进行全量同步;•部分复制:即将未同步的增量数据,同步到从服务器,无需全部再同步一遍;一般用于因网络中断等无法同步数据的情况,待恢复正常之后,将中断期间数据进行部分同步;
为了方便查看日志分析,使用两台 redis 服务器进行搭建主从, 将之前搭建的关系去除,通过修改配置文件重启即可;
这里以 6388 作为主节点(Master),6399 作为从节点(Slave),当连接 6399 执行命令slaveof 127.0.0.1 6388配置主从关系时,主从节点分别打印日志如下:

上图是刚开始建立主从关系时,进行了全量复制,大概流程如下:

简要说明:
1.从节点与主节点建立连接,然后发送同步请求 psync;2.主节点给从节点发送信息,replid 和 offset,这两个参数后续是判断是否部分复制的关键数据;3.主节点 fork 子进程将全部数据生成 RDB 文件;4.主节点期间接收到的写命令存入到复制缓冲区中;5.当主节点 RDB 文件完成之后发送给从节点;6.从节点接收到文件,先清空老数据;7.从节点清空数据后,加载接收到的数据到内存中;8.主节点发送复制缓冲区中的数据到从节点;9.从节点接收到命令并执行,最终同步到最新数据;
主从关系是通过网络进行通讯,可能出现网络中断或网络抖动情况,导致短时间的数据不能及时同步到从节点上,理想情况下,当连接恢复的时候,希望只同步中断期间的数据,从而提高同步效率,部分复制流程大概如下:

简要说明:
1.当主从之间由于网络中断时,从节点会尝试重连主节点;2.在此期间,主节点接收到的写命令会记录到复制缓冲区中;3.当网络恢复,从节点连上主节点,会请求发布同步请求 psync,并带上之前主节点发送过来的 replid 和 offset;4.主节点接收到从节点的请求,会验证接收的 replid 与主节点 replid 是否匹配,不匹配会进行全量复制;还会验证 offset 数据偏移量是否在合法范围内,如果中断期间数据量过大,导致复制缓冲区的数据超出,主从节点的 offset 数据偏移量不一致,也会进行全复制;5.当从节点传递过来的 replid 和 offset 验证通过时,则进行部分复制,并记录最新的 offset;
这里就不模拟演示部分复制流程了,留给小伙伴操作。演示流程如下:已经搭建主从关系的两台机器,手动模拟网络断开,断开期间在主服务器写入数据,一会之后恢复网络,查看主从服务器日志打印情况;
主从复制的相关配置参数
以上演示在配置文件中只是配置了部分参数,还有其他参数的配置可以轻松实现功能,这里结合主从复制的内容可以回顾一下相关配置参数的意义,如下:
•slaveof:设置本机为从机,指定主机的 IP 和端口;•masterauth:如果主机需要密码,通过这设置;•slave-serve-stale-data:从机如果与主机断开或数据正在同步,获取数据是否继续,如果设置为 yes,还可以正常读取数据,设置为 no,获取数据返回错误提示;•slave-read-only:配置从主机为只读模式,默认为 yes,也强烈建议为只读模式;•repl-diskless-sync:是否采用无磁盘方式进行主从传递数据,即采用 Socket 方式,默认没采用,如果机器磁盘性能不好,而网络环境良好,可以尝试使用这种模式;•repl-diskless-sync-delay:当使用无磁盘方式传递数据时,服务器开始传递数据前等待指定时间,等待从服务器进入传输队列,提高数据传输效率,默认为 5 秒;du
主从复制
•repl-ping-slave-period:设置从机向主机发送 ping 消息间隔,即理解为心跳检测;•repl-timeout:设置超时时间,主从机传递数据的时间,如果超过指定时间,从机会重连。一般主从复制数据比较大时,可以将其改大,默认为 60s ;•repl-disable-tcp-nodelay:主从复制数据是否采用 TCP_NODELAY,默认为 no,代表不启用,表示主机立即同步数据,保证数据一致性失效;如果设置为 yes,合并较小的 TCP 包一并发送,延迟高,但可以提升带宽性能,但推荐不启用;•repl-backlog-size:用于设置复制缓冲区的大小,此缓冲区用于从机断开重连之后同步的增量数据,在一定时间内不用全量复制,提升同步效率;默认为 1mb,可以根据需求进行修改;•repl-backlog-ttl:设置从机断开后没有连接主机的间隔时间,超过此时间,设置的 backlog 缓冲区就会释放,默认为 3600s;•slave-priority:用于哨兵模式选择,即当主机挂掉时,选择优先级较高的从机代替挂掉的主机,快速恢复;默认值为 100;•min-slaves-to-write 3:指可用从服务器少于 3 个时,主服务器只能读,不能写,一般和 min-slaves-max-lag 搭配用,默认不使用,根据需要进行配置;•min-slaves-max-lag 10:指从服务器的延迟超过 10 秒时,主服务器也只能读,不能写,一般和 min-slaves-to-write 搭配用,默认不使用,根据需要进行配置;
主从复制有哪些问题
主从复制缓解了单节点性能和存储的瓶颈,那又带来什么问题呢?
•主从复制架构会有延时,尽快很快,也有,特别数据量和并发大的时候;目前的主从架构没有好的方法处理延时,MySql、SqlServer 也是如此;•过期 Key 数据在早期版本不能及时将从服务器数据失效,可以升级到 redis3.2 之后解决,因为加入了过期判断;•主节点宕机之后,只能手动重新配置主从关系,从服务器可以执行slaveof no one命令重写回到主服务器角色,然后重新配置主从关系;•如果从节点过多,当刚开始初始化数据全量同步或多个从节点断开重连时,就会导致主节点的 IO 剧增;
总结
主从复制演练看似简单,但还需要不断在实践中获取经验,搭配相关配置参数,从而使得更加适合应用场景;配置没有固定都一样,而是应用场景是否适合。随着主节点宕机不能自动选举的问题,下次在此基础上说说哨兵模式,让自动选举不是问题。

![【学习强国】[挑战答题]带选项完整题库(2020年4月20日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/timg-300x200.jpg)


![【学习强国】[新闻采编学习(记者证)]带选项完整题库(2019年11月1日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/77ed36f4b18679ce54d4cebda306117e-300x200.jpg)



{kind=link}
{kind=link}