Elasticsearch 是一款功能强大的分布式搜索和分析引擎,被广泛应用于各种场景。
然而,在使用 Elasticsearch 进行查询操作时,可能会遇到一些限制。
这些限制有的是为了防止性能下降和资源耗尽而设定的,有些则是由于软件本身的工作方式所固有的。
深入了解这些查询限制,对于优化性能和确保系统的高效稳定运行至关重要。
Elasticsearch 中的五大查询限制,并提供相应的解决方案和优化建议。

一、结果大小限制(Result Size Limit)
1. 默认限制
Elasticsearch 默认情况下会限制每个搜索查询返回的文档数量。
size 参数控制最大返回结果数,默认值为 10。
如果设置过高的 size 值,可能会导致内存使用量增加,并需要更多的 CPU 和磁盘资源来检索和评分文档。
2. 最大结果窗口
需要注意的是,Elasticsearch 对查询结果的最大限制为 10,000 个文档。超过该值将导致以下错误:
"type": "illegal_argument_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [100000].
See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."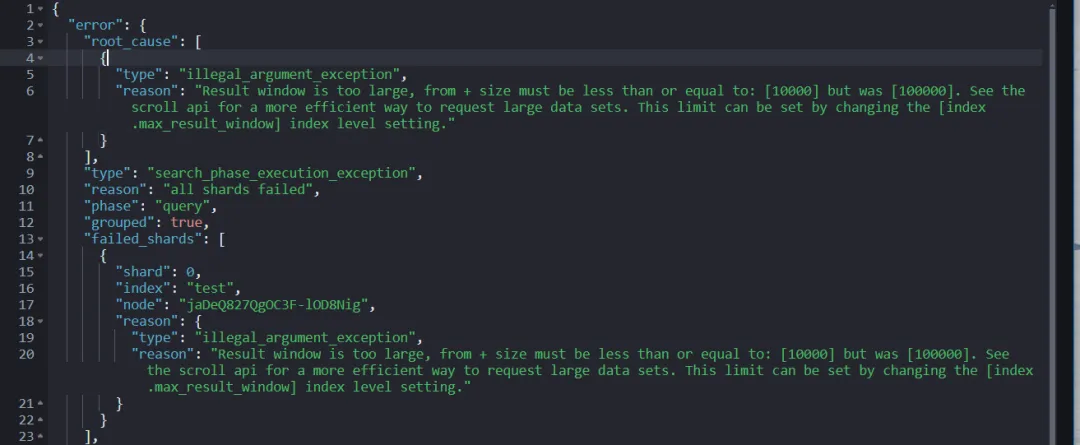
这是由于 index.max_result_window 的默认值为 10,000,目的是防止深度分页导致的性能问题。
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules.html
3. 解决方案
对于需要深度分页的场景,建议使用以下两种方法:
(1)使用 search_after
search_after 参数允许您在不增加 from 和 size 参数的情况下,进行深度分页。它的性能比深度分页要好得多。
示例:
GET /my-index/_search
{
"size": 1000,
"query": {
"match": {
"title": "Elasticsearch"
}
},
"sort": [
{ "timestamp": "asc" },
{ "_id": "asc" }
],
"search_after": [1609459200000, "my_document_id"]
}
(2)使用滚动查询(scroll)
滚动查询适用于一次性检索大量数据的场景,如全量导出。它保持一个服务器端的快照,以确保在遍历结果集时的一致性。
示例:
GET /my-index/_search?scroll=1m
{
"size": 1000,
"query": {
"match": {
"title": "Elasticsearch"
}
}
}
注意:滚动查询不适用于实时用户请求,因为它在服务器端会消耗资源。
干货 | 全方位深度解读 Elasticsearch 分页查询
值得一提的是,咱们常用的工具 elasticdump 就是基于 scroll 实现的。
https://github.com/elasticsearch-dump/elasticsearch-dump
二、最大子句计数限制(Max Clause Count)
1. 背景
Elasticsearch 的核心引擎 Lucene 具有内置的保护机制,可防止执行过于庞大的查询导致系统卡顿。复杂的查询(如包含大量 OR 条件的布尔查询)可能会被重写为包含大量子句的查询,从而消耗大量的内存和计算资源。
2. 默认限制
在早期版本的 Elasticsearch 中,max_clause_count 的默认限制为 1024。
从 Elasticsearch 7.0 版本开始,此值已调整为 4096。如果查询的子句数量超过该限制,Elasticsearch 将抛出异常,拒绝执行该查询。
3. 重要变更(Elasticsearch 8.0 及以上)
在 Elasticsearch 8.0.0 版本中,indices.query.bool.max_clause_count 这个设置已被废弃,不再对查询行为产生影响。

https://www.elastic.co/guide/en/elasticsearch/reference/current/search-settings.html
Elasticsearch 现在会动态地设置查询中允许的最大子句数,使用基于以下因素的启发式算法:
搜索线程池的大小
JVM 分配的堆内存大小
该限制的最小值为 1024,但在大多数情况下会更高。例如:
示例配置:在具有 30GB RAM 和 48 个 CPU 的节点上,最大子句数约为 27,000。
影响因素:
更大的堆内存:会增加最大子句数,因为有更多内存可用于处理复杂查询。
更大的线程池:会减少最大子句数,因为每个并发搜索可用的内存减少了。
4. 注意事项
最大子句计数限制的动态调整机制,使 Elasticsearch 能够更智能地管理资源,防止单个查询过度消耗内存。
然而,这也要求我们在设计查询时更加谨慎,避免过度依赖大量子句的复杂查询。
通过优化查询方式和合理配置资源,可以有效应对新的限制,确保系统的稳定性和高性能。
三、字段数据限制(Field Data Limits)
1. 问题描述
在聚合和排序操作中,Elasticsearch 可能需要将字段的数据加载到内存(堆)中。对于高基数(cardinality)的字段(如唯一值很多的字段),这可能导致内存使用量过高,甚至引发 OutOfMemoryError。
2. 优化策略
(1)限制字段数据缓存大小
可以通过设置 indices.fielddata.cache.size 来限制字段数据缓存的堆内存使用量。
indices.fielddata.cache.size: 40%https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-fielddata.html
上述配置将字段数据缓存限制为堆内存的 40%。
(2)使用预聚合指标
对于需要频繁聚合的字段,考虑在索引阶段预先计算好指标,存储为文档的一个字段,减少实时聚合的计算量。可以参考如下文章中的实战案例。
(3)避免在文本字段上聚合
尽量避免对 text 类型的字段进行聚合,因为它们需要进行分析(分词)才能聚合。
可以使用 keyword 类型的字段替代。
四、多表关联操作限制(Joins)
1. 问题描述
复杂的多表连接接操作(如嵌套查询、父子关系查询)会给集群带来显著的负载。
如果查询过于复杂,可能会触发 max_clause_count 等限制,Elasticsearch 可能会拒绝执行此类查询。
2. 注意事项
(1)避免关系型思维
Elasticsearch 是面向文档的存储,而非关系型数据库。试图在其中实现关系型数据库的星型或雪花型模式是不可行的。
(2)慎用嵌套和父子关系
虽然可以使用嵌套(nested)或父子(parent-child)关系来实现一定程度的联接,但这会增加索引和查询的复杂度,以及系统的开销。
干货 | Elasticsearch 多表关联设计指南
3. 建议
(1)扁平化宽表数据结构
在索引阶段,尽可能地扁平化数据结构,将相关的数据放在同一个文档中。
这可能会增加数据冗余,但会显著提高查询性能。
(2)利用应用层连接
如果必须进行复杂的多表关联操作,考虑在应用层(如应用服务器或客户端)进行数据组合,而非依赖 Elasticsearch。
五、查询吞吐量限制(Query Throughput)
1. 理解查询吞吐量
每个 Elasticsearch 集群都有其最大查询吞吐量,这取决于节点数量、硬件配置和查询的复杂度。
当查询请求超过集群的处理能力时,响应时间会增加,甚至可能导致请求被拒绝。
2. 计算示例
假设:
每个查询耗时:1 秒
数据节点数量:3 个
每个节点的搜索线程数:13 个(取决于 CPU 核心数)
最大吞吐量(仅供参考):
最大查询吞吐量 = 数据节点数 × 每节点搜索线程数 / 查询耗时
最大查询吞吐量 = 3 × 13 / 1 = 39 个查询/秒
3. 保护机制
(1)搜索队列(Search Queue)
当请求数量超过线程处理能力时,新的查询会被放入搜索队列。
当队列达到最大长度时,Elasticsearch 将返回 HTTP 429 错误,拒绝新的请求。
(2)断路器(Circuit Breaker)
为防止内存溢出或堆耗尽,Elasticsearch 实施了断路器机制。
当查询或操作超过预设的资源限制时,断路器会触发并中止操作,以保持系统稳定。
4. 优化建议
(1)监控查询性能
使用监控工具(如 Kibana、Elastic Stack Monitoring)定期监控查询的响应时间和资源消耗。
识别并优化慢查询,调整查询方式或增加必要的索引。
(2)增加硬件资源
扩展集群:增加数据节点数量,分散查询负载。
升级硬件:提升节点的 CPU、内存和存储性能(结合公司实际,等 Leader 拍板才可以)。
(3)合理设置超时
在发送请求时,设置合理的超时时间,避免长时间占用系统资源。
(4)处理 HTTP 429 响应
当收到 HTTP 429(Too Many Requests)错误时,不要立即重试请求。
应实现指数退避(Exponential Backoff)策略,延迟一段时间后再重试。通俗一点说:如果请求被拒绝,不要立即重试,而是先等一会儿再试,而且每次等待的时间要比上次更长。
总结
深入了解 Elasticsearch 的查询限制,对于优化性能和确保系统稳定性至关重要。
通过合理配置参数、监控资源使用情况,以及设计合适的数据模型,可以有效避免触及这些限制,从而提升整体搜索体验。
提示:OpenSearch 与 Elasticsearch 原理相同,可以一并参考本文。
参考:https://bigdataboutique.com/blog/elasticsearch-and-opensearch-query-limits-145927

![【学习强国】[挑战答题]带选项完整题库(2020年4月20日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/timg-300x200.jpg)


![【学习强国】[新闻采编学习(记者证)]带选项完整题库(2019年11月1日更新)-武穆逸仙](https://www.iwmyx.cn/wp-content/uploads/2019/12/77ed36f4b18679ce54d4cebda306117e-300x200.jpg)

{kind=link}
{kind=link}